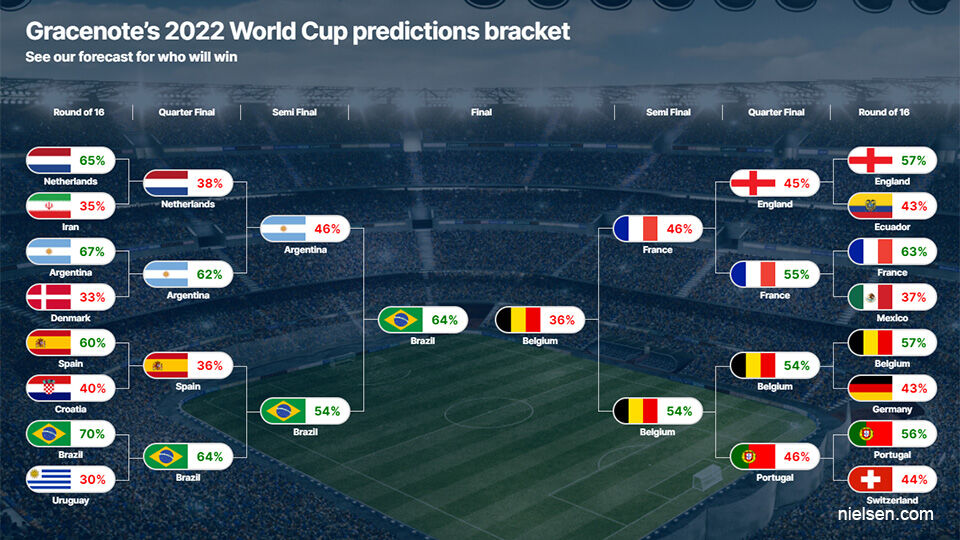
We worden de laatste dagen om de oren geslagen met (wetenschappelijke) WK-simulaties. Maar waarom verschillen die soms zo sterk? En wat is het nut ervan? Twee experts aan het woord: "Het hangt af van welke informatie je gebruikt."
Waarom verschillen voorspellingen?
"De verschillen tussen de verschillende simulaties hangen af van de informatie die het model gebruikt en hoeveel waarde je aan welke factoren hecht," aldus Jan Van Haaren, data-wetenschapper bij KU Leuven en -analist voor Club Brugge.
Zo gebruikt het model van de KU Leuven bijvoorbeeld de marktwaarde van een ploeg en geeft het meer gewicht aan recentere resultaten.
Dat is het grote verschil met Gracenote, zegt computerwetenschapper Pieter Robberechts, die betrokken was bij de studie van de KU Leuven: "Gracenote kiest enkel voor de ELO-ratings, gelijkaardig aan de FIFA-ranglijst, om winstkansen te berekenen. Daar staat België hoger dan Portugal."
Van Haaren combineerde daarom de voorspellingen van een zestiental modellen: "Dan krijg je een soort wisdom of the crowd effect. Individuele modellen zullen wellicht niet de perfecte waarde hechten aan bepaalde factoren, maar allemaal samen kunnen ze dat veel beter."
Wat is het nut van zulke simulaties?
"De uitkomst op zich is niet zo interessant, maar het is wel interessant hoe je daaraan komt. Het leuke is dus dat ze een verhaal vertellen," zo stelt Robberechts.
"Zo staat België vooral hoog op de FIFA-ranglijst, maar wordt hun team ouder en verliezen ze daarom aan marktwaarde."
Het zet mensen aan om erover te discussiëren.
"Het is ook gewoon leuk. Het is gespreksstof en zet mensen aan om te discussiëren over die voorspellingen. Veel mensen zijn daar benieuwd naar, zeker voor een WK," besluit Van Haaren.